Very often we come across indicator functions denoting class membership. These functions in their native form are neither continuous nor differentiable. I will describe a trick to convert such indicator functions to an approximate continuous and differentiable function. This blog is organized as follows:
- Describe a computation case with indicator function
- Trick to convert
- More remarks on why and how it works
Computation case with indicator function
Imagine you have several (say 250) 10-dimensional vectors 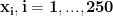
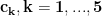
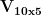




Here, 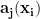

Such computations are reasonably common. This computation is for Vector of Locally Aggregated Descriptors (VLAD) [1,2]. Description here adopted from NetVLAD paper, in particular, see vlad. Another example I can think of for similar computation is the K-means clustering.
Trick to Convert to Continuous and Differentiable Computation
The computation at hand (Eq. 1) is noncontinuous and nondifferentiable. This happens due to the nature of class indicator function ie. $latex \bf{a}_j(\bf{x}_i)$. However, we can approximate this with another continuous and differentiable function as :
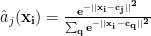
Now, if you use 

More Remarks
Plot of 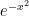


References
- Arandjelovic, Relja, and Andrew Zisserman. “All about VLAD.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2013.
- Jégou, Hervé, et al. “Aggregating local descriptors into a compact image representation.” Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010.
